ServiceNow Foundation Data: Automatische Synchronisation mit Azure Automation
Jedes ServiceNow-Modul baut auf Foundation Data auf. Incident Management braucht korrekte Users und Groups. Asset Management braucht aktuelle Locations und Cost Centers. Die CMDB verlässt sich auf Departments und Companies für die Ownership-Zuordnung.
Wenn Foundation Data falsch ist, ist alles was darauf aufbaut auch falsch. Und in den meisten Organisationen ist Foundation Data zumindest teilweise fehlerhaft.
Die Ursache ist fast immer dieselbe: manuelle Prozesse. Jemand exportiert ein CSV aus SAP HR, formatiert es um und importiert es in ServiceNow. Jemand anders aktualisiert Active Directory Gruppen, vergisst aber die Änderungen zu synchronisieren. Abteilungen werden reorganisiert, und die ServiceNow-Tabellen spiegeln die Realität wochenlang nicht wider.
Die Lösung sind nicht bessere Spreadsheets. Es ist Automatisierung.
Was ist Foundation Data in ServiceNow?
Foundation Data bezeichnet die zentralen Referenztabellen, auf denen jedes andere ServiceNow-Modul aufbaut. Wer ServiceNows Common Service Data Model (CSDM) kennt, erkennt diese sofort:
- Users (sys_user) – Mitarbeiter, Externe, Service Accounts
- Groups (sys_user_group) – Support-Teams, Genehmigungsgruppen, Zuweisungsgruppen
- Locations (cmn_location) – Büros, Rechenzentren, Lager
- Companies (core_company) – Gesellschaften, Lieferanten, Partner
- Departments (cmn_department) – Organisationseinheiten
- Cost Centers (cmn_cost_center) – Kostenstellen
- Business Units (business_unit) – Übergeordnete Organisationseinheiten
Keine glamourösen Tabellen. Niemand wird aufgeregt, wenn es um die Pflege von Location-Records geht. Aber wenn ein User ein Incident meldet und seine Abteilung falsch hinterlegt ist, wird es ans falsche Team geroutet. Wenn eine Kostenstelle fehlt, stimmt das Financial Reporting nicht. Wenn ein Standort nicht existiert, bricht das Asset Tracking zusammen.
Foundation Data ist die unspektakuläre Infrastruktur, die alles andere zum Laufen bringt.
Warum manuelle Synchronisation scheitert
Wir haben mit Organisationen von 500 bis 50.000 Mitarbeitern gearbeitet. Das Muster ist unabhängig von der Größe dasselbe. Manuelle Foundation-Data-Pflege scheitert aus vorhersehbaren Gründen.
Mehrere Quellsysteme. Users leben in Active Directory und Entra ID. Organisationsstrukturen kommen aus SAP HR oder Workday. Locations stecken vielleicht in einem Facility-Management-System. Cost Centers kommen aus dem ERP. Kein einzelnes System hat das vollständige Bild.
Update-Frequenz. Leute kommen und gehen. Abteilungen werden umstrukturiert. Büros öffnen und schließen. In einem Unternehmen mit 5.000 Mitarbeitern gibt es Dutzende Änderungen pro Woche. Manuelle Prozesse halten ohne dediziertes Personal nicht Schritt.
Menschliche Fehler. Jemand tippt „IT Operations“ in einem System und „IT-Operations“ in einem anderen. Ein Standort wird hier als „Wien Büro“ und dort als „Vienna Office“ eingetragen. Diese Inkonsistenzen ziehen sich durch jeden Prozess, der die Daten nutzt.
Kein Audit Trail. Wenn Daten manuell per CSV importiert werden: Wer hat wann was geändert? Viel Spaß bei der Beantwortung dieser Frage im Compliance-Audit.
→ Vermeiden Sie die häufigsten Fehler: Die 10 häufigsten Azure Automation Fehler
Die Architektur der automatisierten Synchronisation
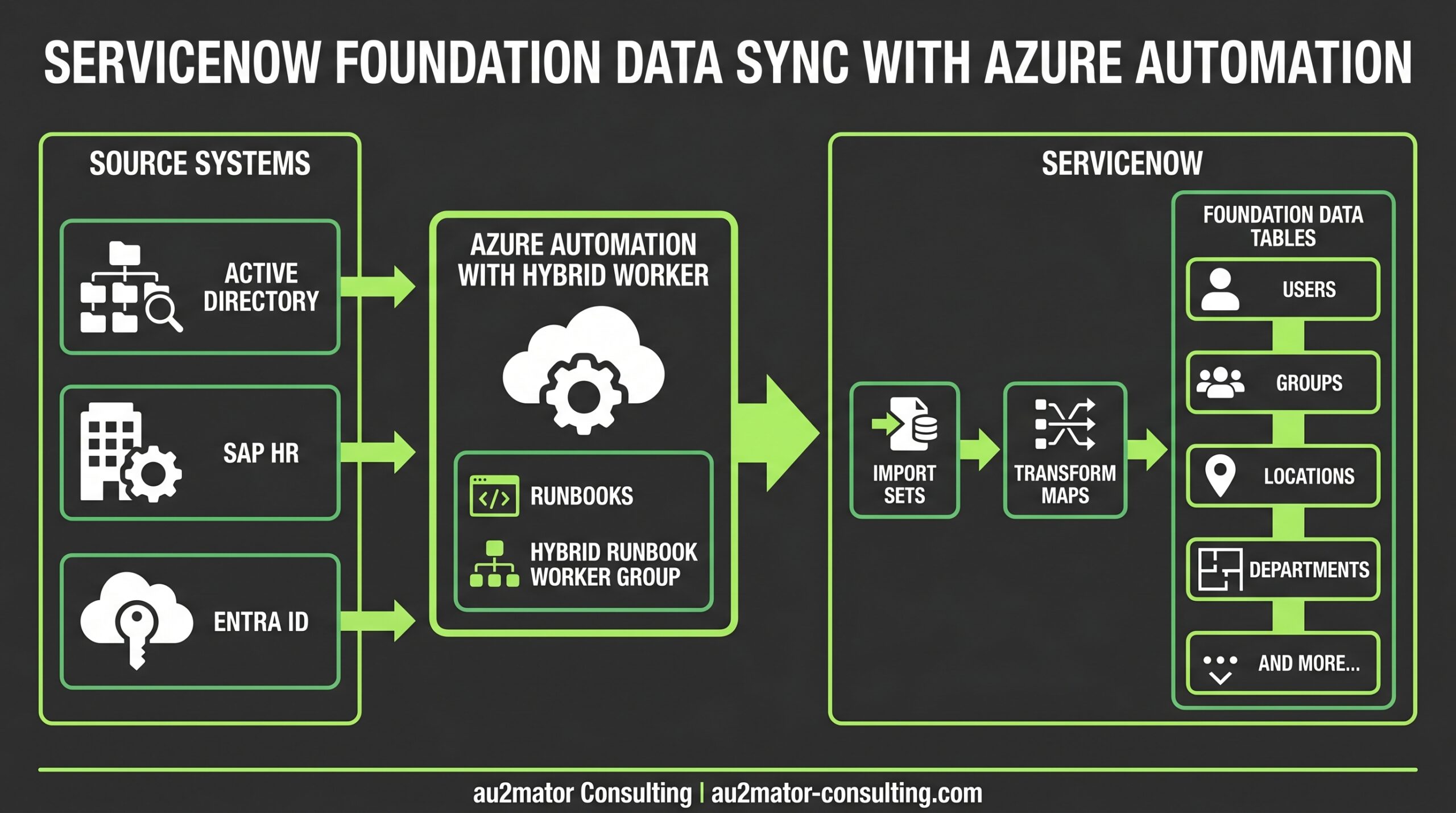
Die Architektur für automatisierte Foundation-Data-Synchronisation ist geradlinig. Drei Schichten, jede mit einer klaren Verantwortung.
Quellsystem-Schicht
Hier leben die autoritativen Daten:
- Active Directory / Entra ID für Benutzerkonten, Gruppenmitgliedschaften und einige organisatorische Attribute
- SAP HR / SuccessFactors / Workday für Organisationsstrukturen, Abteilungen, Kostenstellen, Vorgesetzten-Beziehungen
- Facility- oder ERP-Systeme für Standorte, Gesellschaften, Business Units
Das Schlüsselprinzip: Jedes Datenattribut hat genau eine autoritative Quelle. Die E-Mail des Users kommt aus Entra ID. Seine Abteilung kommt aus SAP HR. Sein Bürostandort kommt aus dem Facility-System. Keine Konflikte, keine Mehrdeutigkeit.
Azure Automation Schicht
Azure Automation fungiert als Integrations-Engine. Runbooks ziehen Daten aus Quellsystemen, transformieren sie in das von ServiceNow erwartete Format und pushen sie via REST API nach ServiceNow.
Für On-Premises-Quellen wie Active Directory läuft ein Hybrid Runbook Worker im Unternehmensnetzwerk. Der kann AD per LDAP erreichen und ServiceNow per HTTPS. Keine VPN-Tunnel oder komplexen Firewall-Regeln nötig für die ServiceNow-Seite.
Für Cloud-Quellen wie Entra ID oder SuccessFactors laufen Runbooks in der Azure Sandbox oder auf einem Cloud-verbundenen Hybrid Worker. Authentifizierung nutzt Managed Identity für Azure-Ressourcen und gespeicherte Credentials (via Key Vault) für Drittanbieter-APIs.
Ein typisches Sync-Runbook folgt diesem Ablauf:
1. Mit Quellsystem verbinden (AD, Entra ID, SAP API)
2. Änderungen seit letztem Sync abfragen (Delta) oder alle Datensätze (Full)
3. Daten in ServiceNow Import Set Format transformieren
4. Records per POST an ServiceNow Import Set API senden
5. Transform Map auslösen zur Verarbeitung
6. Ergebnisse loggen und Fehler behandelnServiceNow-Schicht
Daten gelangen über Import Sets und Transform Maps nach ServiceNow. Das ist entscheidend. Niemals direkt in Produktivtabellen wie sys_user oder cmn_department schreiben.
Import Sets sind Staging-Tabellen. Daten landen zuerst dort. Transform Maps wenden dann Geschäftsregeln an: Feldmapping, Datenvalidierung, Coalesce-Logik (Abgleich) zum Aktualisieren bestehender oder Anlegen neuer Records, und alle nötigen Transformationen.
Dieser zweistufige Ansatz bietet:
- Validierung bevor Daten in Produktivtabellen landen
- Fehlerbehandlung mit klaren Logs was transformiert wurde und was nicht
- Rollback-Fähigkeit weil Import Sets die Originaldaten behalten
- Audit Trail der zeigt was reinkam und was sich geändert hat
Praxisbeispiel: Fertigungsunternehmen
Ein Fertigungsunternehmen mit 5.000 Mitarbeitern an 12 Standorten hatte ein bekanntes Problem. Benutzerdaten lebten im Active Directory. Die Organisationshierarchie kam aus SAP HR. Standortdaten wurden manuell in ServiceNow von zwei Admins gepflegt.
Die Ergebnisse waren vorhersehbar. Bei 15% der User stimmte die Abteilungszuordnung nicht. Mehrere Standorte existierten als Duplikate mit leicht unterschiedlichen Namen. Kostenstellen-Zuordnungen waren monatelang veraltet. Jeder CMDB-Report, der auf diesen Beziehungen aufbaute, lieferte fragwürdige Ergebnisse.
Wir haben eine automatisierte Synchronisation mit drei Runbooks implementiert:
User Sync (alle 2 Stunden):
- Fragt Entra ID über Microsoft Graph API nach allen aktiven Usern
- Zieht Abteilung, Kostenstelle und Vorgesetzten aus SAP HR über OData API
- Führt Daten anhand der Personalnummer zusammen
- Pusht in ServiceNow sys_user Import Set
- Transform Map gleicht auf employee_number ab, aktualisiert bestehende User, legt neue an
Group Sync (alle 4 Stunden):
- Fragt Active Directory nach Security Groups mit definierter Namenskonvention
- Mappt Gruppenmitgliedschaft auf ServiceNow sys_user_group und sys_user_grmember
- Handhabt verschachtelte Gruppen durch Auflösen der Hierarchie
Standort- und Org-Struktur Sync (täglich):
- Zieht Standorte, Abteilungen, Kostenstellen und Business Units aus SAP HR
- Pusht in die jeweiligen ServiceNow Import Sets
- Handhabt Parent-Child-Beziehungen (Abteilungshierarchie, Standorthierarchie)
Die Ergebnisse nach drei Monaten:
- Datengenauigkeit verbessert von ca. 85% auf 99,2%
- Manueller Pflegeaufwand um 90% reduziert
- Neue Mitarbeiter erschienen innerhalb von 2 Stunden in ServiceNow statt nach Tagen
- CMDB-Beziehungsmapping hatte endlich ein verlässliches Fundament
Delta Sync vs Full Sync
Diese Frage kommt in jedem Projekt. Soll das Runbook jedes Mal alle Datensätze synchronisieren oder nur Änderungen?
Full Sync ist einfacher zu implementieren. Alles abfragen, alles pushen, die Transform Map sortiert es. Für kleine Datenmengen (unter 5.000 Datensätze) funktioniert Full Sync alle paar Stunden problemlos. Es ist auch die sicherere Option, wenn Quellsysteme Änderungen nicht zuverlässig nachverfolgen.
Delta Sync ist bei großen Datenmengen nötig. Bei 50.000 Usern alle 2 Stunden alles abzufragen und zu pushen, belastet jedes System in der Kette unnötig. Delta Sync fragt nur Datensätze ab, die seit dem letzten erfolgreichen Lauf geändert wurden.
Implementierungsansatz für Delta Sync:
# Letzten Sync-Zeitstempel aus Automation Variable lesen
$lastSync = Get-AutomationVariable -Name "UserSync_LastRun"
# Entra ID nach Usern fragen, die seit letztem Sync geändert wurden
$filter = "lastModifiedDateTime ge $lastSync"
$modifiedUsers = Get-MgUser -Filter $filter -All
# Nach erfolgreichem Sync Zeitstempel aktualisieren
Set-AutomationVariable -Name "UserSync_LastRun" -Value (Get-Date -Format "yyyy-MM-ddTHH:mm:ssZ")Unsere Empfehlung: Mit Full Sync starten. Die Pipeline end-to-end zum Laufen bringen. Dann auf Delta Sync optimieren, sobald der Prozess validiert ist. Vorzeitige Optimierung fügt Komplexität hinzu, bevor der Ansatz bewiesen ist.
Fehlerbehandlung und Validierung
Sync-Runbooks brauchen robuste Fehlerbehandlung. Wenn man Tausende Records pusht, werden manche fehlschlagen. Die Frage ist: Weiß man welche und warum?
Vor-Validierung im Runbook:
- Pflichtfelder prüfen bevor man an ServiceNow sendet (E-Mail, Personalnummer, Abteilung)
- Datenformate validieren (Datumsfelder, E-Mail-Syntax)
- Records die Kriterien nicht erfüllen markieren, aber den gesamten Sync nicht stoppen
Transform Map Fehlerbehandlung:
- ServiceNow Transform Maps haben eingebaute Fehlerbehandlung pro Record
- „Stop on error“ nur konfigurieren wenn ein einzelner fehlerhafter Record den Import stoppen soll
- Normalerweise: „Log and continue“, damit ein fehlerhafter Record nicht 4.999 gute blockiert
Post-Sync Validierung:
- Nach dem Sync eine Validierungsabfrage ausführen: Wie viele Records wurden verarbeitet? Wie viele erstellt, aktualisiert, übersprungen, Fehler?
- Anzahlen zwischen Quelle und Ziel vergleichen
- Bei Anomalien alerten (z.B. wenn mehr als 5% der Records fehlerhaft sind)
Scheduling Best Practices
Nicht alle Foundation Data ändern sich gleich schnell. Die Sync-Schedules sollten das reflektieren.
Users: Alle 1-2 Stunden. Neue Mitarbeiter und Austritte brauchen schnelle Propagierung.
Group Membership: Alle 2-4 Stunden. Zuweisungsgruppen beeinflussen Incident-Routing.
Departments: Täglich. Reorganisationen passieren nicht stündlich.
Locations: Täglich oder wöchentlich. Büros ziehen nicht oft um.
Cost Centers: Täglich. Änderungen sind an Geschäftsperioden gebunden.
Companies: Wöchentlich. Gesellschaften ändern sich selten.
Schedules staffeln. Nicht alle Syncs gleichzeitig laufen lassen. Wenn der User Sync um :00 und :30 läuft, den Group Sync auf :15 und :45 legen. Das vermeidet, dass die ServiceNow Import Set API mit parallelen Lasten bombardiert wird.
FAQ
Was tun wenn dieselben Daten in mehreren Quellsystemen existieren?
Eine einzelne autoritative Quelle pro Attribut definieren. Name und E-Mail kommen aus Entra ID. Abteilung und Kostenstelle kommen aus SAP HR. Diese Zuordnungen dokumentieren und in den Runbooks durchsetzen. Nie widersprüchliche Werte zusammenführen ohne klare Vorrangregel.
Wie geht man mit gelöschten Usern oder deaktivierten Konten um?
Records in ServiceNow nicht löschen. Auf inaktiv setzen. Das Sync-Runbook vergleicht Quell-Records mit ServiceNow, und jeder ServiceNow-Record ohne passenden Quell-Record wird als inaktiv markiert. Das bewahrt historische Daten und Audit Trails.
Was ist mit ServiceNows eingebauter LDAP-Integration?
ServiceNow hat native LDAP- und Azure-AD-Integrationen. Die funktionieren für einfachen User-Sync. Aber sie decken komplexe Szenarien nicht ab: Daten aus mehreren Quellen zusammenführen, Custom Business Logic beim Import, oder Nicht-User Foundation Data wie Kostenstellen und Business Units synchronisieren. Azure Automation gibt die volle Kontrolle über die Integrationslogik.
Wie lange dauert ein typisches Foundation Data Automatisierungsprojekt?
Für ein einzelnes Quellsystem (z.B. Entra ID nach ServiceNow Users und Groups): 2-4 Wochen inklusive Entwicklung, Test und Dokumentation. Für Multi-Source-Szenarien mit komplexen Geschäftsregeln: 6-10 Wochen sind realistisch. Die Transform Map Konfiguration in ServiceNow dauert oft länger als die Runbook-Entwicklung.
Kann dieser Ansatz speziell SAP HR Daten verarbeiten?
Ja. SAP stellt Organisationsdaten über OData APIs (SuccessFactors) oder RFC/BAPI-Aufrufe (On-Premise SAP) bereit. Azure Automation Runbooks können diese APIs direkt aufrufen. Für On-Premise SAP: Einen Hybrid Runbook Worker im Netzwerk einsetzen, der das SAP-System erreichen kann. Wir haben das bei mehreren Kunden mit SAP als HR-Mastersystem implementiert.
Datenqualität in ServiceNow nicht zufriedenstellend? Wir konzipieren und implementieren automatisierte Sync-Lösungen, die Ihre Quellsysteme mit ServiceNow verbinden. Saubere Daten, zuverlässige Prozesse, null manueller Aufwand.